上一篇有提到激勵函數,但只了解到用來引入非線性資料。可是什麼是非線性資料?sigmoid, tanh, Relu有什麼差別⋯⋯等等,因此這篇就詳細介紹一下。
線性關係:在代數學和數學分析學中,如果一種運算同時滿足特定的「加性」和「齊性」,則稱這種運算為線性。
取自線性關係-維基百科
也就是當輸入值變動時,加性是輸出值會以一定的數字加減來變動,則齊性是一定的倍數變動。以齊性舉例來說,如果今天的時薪忽然從160元變成1600元,變成10倍,會讓人很開心,但是全部物價也上漲10倍,就沒什麼差別了,如果全部物價上漲5倍,這樣還能控制自己目前的花費,而且也知道以前消費跟現在的差別。可是如果是非齊性的話,也就是薪水提升10倍,但是每個產品的價格增加不同,有5倍、10倍、15倍之類的,則就是非齊性,很難去控制自己的預算。
類神經網路亦是這樣,非線性資料輸入了之後,可能只是調整一下參數,每一筆輸出又都不一樣,無法掌握到其中的邏輯,因此就難以掌控。所以才要轉成線性資料來處理。
如果以圖形來看,線性以及非線性的關係就如同圖(一):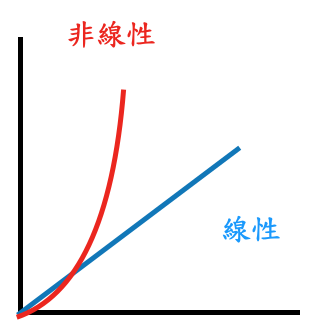
圖(一) 線性以及非線性的關係
線性資料以及非線性資料的形成,是當資料一筆筆輸入的時候,會分散在不同的座標位置上,機器學習的目的就是要找出其中的關聯性,連成一條線。但是不可能把每個點跟點之間連接,因為這樣關係會變得非常複雜,因此要取各點之間距離基準線最小的,來當作邏輯上的判斷,所以大多數時候會非線性資料,很難有線性資料,因為非線性的準確率會比線性高很多。圖(二)中若要線性的話則要形成藍色的線,可是點與線會有很大的落差,若要減小則要形成紅色的線,但就會是非線性資料,在訓練上有一定難度,但點距離線會更近了一點。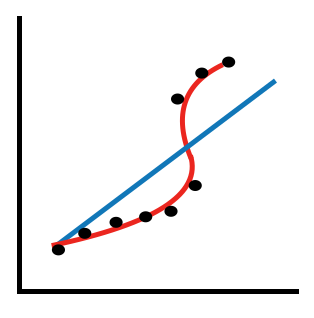
圖(二)線性與非線性的不同狀況
那麼激勵函數是如何把非線性轉換為線性呢?
在非線性函數,找一條基準線,類似用投影的方式,變成線性的。可參考圖(三)。這樣能使類神經網路學習更為方便。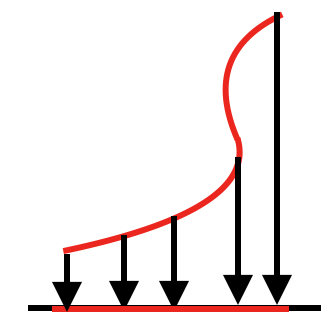
圖(三)激勵函數如何把非線性轉換為線性
最後激勵函數中,sigmoid, tanh, Relu有什麼差別?
首先看到sigmoid, tanh, Relu這三個分別的數學代表式,如下圖: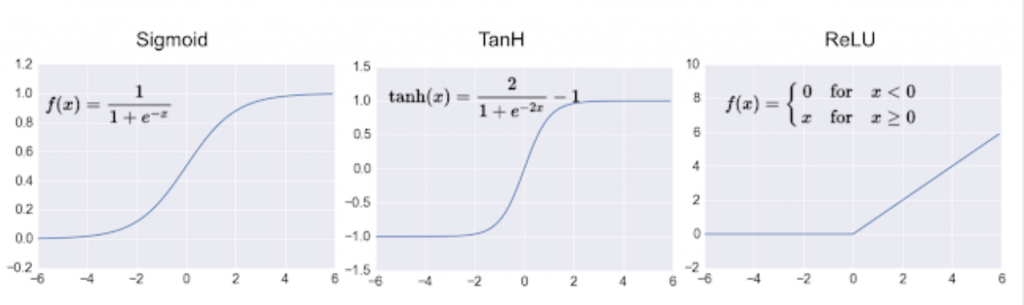
圖(四)sigmoid, tanh, Relu數學代表式。圖片來源:深度學習:使用激勵函數的目的、如何選擇激勵函數 Deep Learning : the role of the activation function
在sigmiod中,主要會把任何圖形映射在0、1之間,如果在做二分類會很方便,只要調整設定值,比如大於0.5就是1(程式上表示正確),小於0.5為0(程式上表示錯誤),但要注意這方式有可能會造成梯度消失,在梯度下降法篇中最後一張圖就是梯度消失問題。而且實際上電腦計算不容易,因為要用到指數,若資料或層數複雜時,則可能無法有效率的進行運算。
則tanh函數,是sigmoid向下平移、收縮的結果,其原理差不多,因此也會有共同的缺點。
最後Relu是最常被使用的,因為它模擬出一般生物上在遇到問題時,有些神經元並不會有反應,維持0的狀態,只會在有需要被使用的時候,才會有反應。再來可以不需要用到指數計算,只要判斷是否大於0即可。也能克服梯度消失問題,還能避免類神經網路的稀疏性等問題。因此若需要進行類神經網路訓練的時候,最好使用Relu比較方便。

